|
Один из участников форума, комментируя "Тест оценки потребления системных ресурсов процессами MS Windows", написал: "постоянно что-то горит". Немногословный господин, вероятно, хотел сказать, что пороговые значения измеряемых метрик, заданные по умолчанию, показывают, что его сервер перегружен, хотя он так не считает. Архимед как-то сказал: "Дайте мне точку опоры, и я сдвину землю". Применительно к мониторингу сети это может звучать так: "Скажите мне пороговые значения (измеряемых метрик), и я быстро диагностирую любой инцидент". Вопрос только, кто их должен сказать? С точки зрения вышеупомянутого господина, наверное, это должна быть компания ProLAN. Но это не совсем так.
Определение пороговых значений метрик "здоровья" ИТ-Инфраструктуры – это обязанность администратора сети. Исключением являются пороговые значения, прописанные в промышленных стандартах (TIA/EIA) и документах регулирующих органов, например, приказах Мининформсвязи. Как правило, они относятся к метрикам, характеризующим качество передачи данных (QoS): delay, jitter, packet loss и т. д. Все остальные, в том числе рекомендации Oracle, Microsoft и даже ProLAN :), это не более чем рекомендации. Наивно полагать, что кто-то вам скажет пороговые значения, идеально подходящие для вашей сети. Вы можете взять эти рекомендации за основу, но вам все равно придется адаптировать их под вашу сеть (правильнее – под ваши бизнес-приложения).
Мне известны три метода определения (адаптации) пороговых значений:
- Метод Базовых Линий.
- Регрессионный анализ – определение зависимости времени реакции бизнес-приложений от значений метрик, характеризующих "здоровье" ИТ-Инфраструктуры.
- Красная Кнопка.
Метод Базовых Линий
Первый способ определения пороговых значений, метод Базовых Линий, является сегодня самым распространенным. Базовая Линия – это метрика или набор метрик, характеризующих нормальную (обычную) работу ИТ-Инфраструктуры. Чтобы построить Базовую Линию, нужно статистически обработать результаты измерений, полученные за длительный период времени, например, за месяц, и получить "усредненное" значение, которое принимается за норму. Значение, превышающее (по модулю) норму, например, на 10%, 30% или 50% (определяется интуитивно) - принимается в качестве порогового значения, соответствующего оценке "плохо".
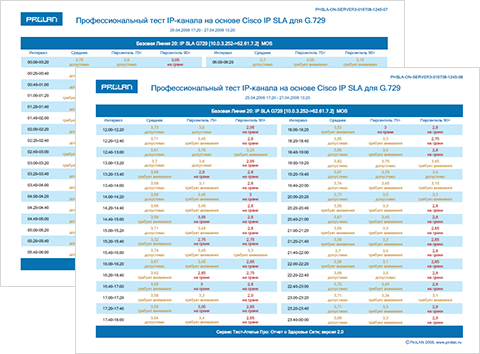
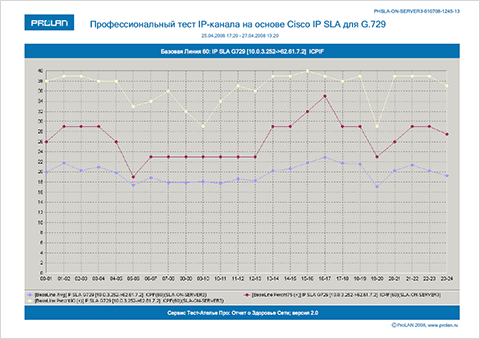
Во многих системах мониторинга сети Базовые Линии строятся автоматически. Существует много способов вычисления и видов представления Базовых Линий. В простейших системах мониторинга – это может быть среднее значение метрики, отображаемое в виде прямой линии, пересекающей график измеряемой метрики. В профессиональных системах – это несколько статистических оценок (как правило, перцентиль), "привязанных" ко времени. Это означает, что значения Базовой Линии, например, в 7-00 и в 11-00 – это два разных значения. На Рисунках 1 и 2 показаны примеры Базовых Линий, автоматически вычисляемых продуктами ProLAN. Базовая Линия 20 оценивает метрики в 20-минутных интервалах и имеет вид таблицы. Базовая Линия 60 оценивает метрики в 60-минутных интервалах и имеет вид трех графиков: среднее значение, перцентиль 75 (отбрасывается 25% худших значений), перцентиль 90 (отбрасывается 10% худших значений).
Достоинство метода Базовых Линий – его простота. Основных недостатков два. Во-первых, "как всегда" и "хорошо" - это не всегда одно и то же. Во-вторых, непонятно, какое отклонение от нормы считать инцидентом, интуиция может подвести.
Регрессионный Анализ
Второй способ определения пороговых значений основан на определении зависимости времени реакции бизнес-приложений (End to End Response Time, E2E RT) от значений метрик, характеризующих "здоровье" ИТ-Инфраструктуры. Идея метода в следующем. В течение представительного периода времени измеряется E2E RT и метрики "здоровья" ИТ-Инфраструктуры, после чего строится зависимость E2E RT от метрик "здоровья" ИТ-Инфраструктуры, оказывающих наибольшее влияние на E2E RT (определяется методом Факторного Анализа). Получив такую зависимость и зная требуемое значение E2E RT, легко определить соответствующие пороговые значения метрик "здоровья" ИТ-Инфраструктуры. Данный способ позволяет очень точно определять пороговые значения. Метод поддерживается, в частности, продуктом Trend Analyst, подробнее см. корреляционный анализ, регрессионный анализ.
Однако, несмотря на то, что метод очень эффективен, используется он не часто. Причина - лень и неумение (нежелание) измерять E2E RT. Измерение E2E RT – это важный вопрос, заслуживающий отдельной статьи. Поэтому сейчас лишь скажу, что на момент написания данной статьи продукты ProLAN поддерживают два метода измерения E2E RT: Transaction Simulation и Application Instrumentation. Метод Client Instrumentation (E2E RT "вытаскивается" из ОС MS Windows на стороне клиента) сейчас находится в стадии разработки. Еще один метод – Network Sniffing (E2E RT "вытаскивается" из сетевого трафика) поддерживается анализатором протоколов GigaStor, дистрибьютором которого является компания ProLAN.
Красная Кнопка
Третий способ определения пороговых значений – Красная Кнопка, по точности и трудоемкости - компромисс между первыми двумя. По точности он практически не уступает второму способу (определение зависимости времени реакции бизнес-приложений от "здоровья" ИТ-Инфраструктуры). По сложности реализации – близок к первому способу (построение Базовой Линии).
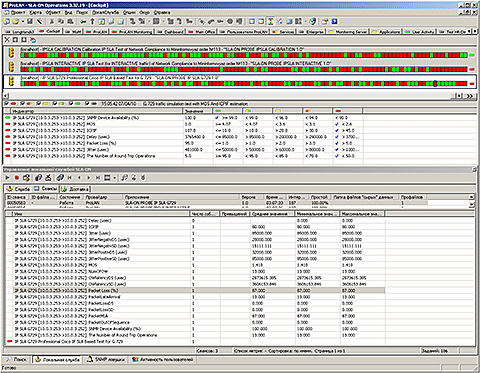
Идея метода очень проста. ИТ-Служба просит пользователей бизнес-приложений нажимать Красную Кнопку (определенную комбинацию клавиш) в те моменты времени, когда с их точки зрения бизнес-приложения работают слишком медленно (при этом trouble tickets не открываются). При этом на компьютерах пользователей установлен специальный агент, который автоматически определяет, с каким бизнес-приложением в каждый момент времени работает пользователь. Одновременно система мониторинга сети измеряет значения метрик, характеризующих "здоровье" ИТ-Инфраструктуры. Жалобы пользователей (нажатие Красной Кнопки) и метрики "здоровья" ИТ-Инфраструктуры автоматически привязываются к единой временной шкале. В результате ИТ-Служба видит, при каких значениях метрик "здоровья" ИТ-Инфраструктуры пользователи жалуются на медленную работу бизнес-приложений. На Рисунке 3 показан пример карты Cockpit приложения SLA-ON Operations, на которой соответствующее пороговое значение отмечается галочкой синего цвета в средней части экрана.
Пользуясь случаем, отвечу на часто задаваемый вопрос: почему в Оценочных Тестах задается пять пороговых значений – хорошо, допустимо, требует внимания, на грани, плохо. Ведь для диагностики инцидентов достаточно было бы одного, соответствующего оценке "плохо"?
Пять пороговых значений необходимы для того, чтобы не пропустить инциденты и не видеть их там, где их нет. Предположим, что по умолчанию задавалось бы только одно пороговое значение, соответствующее оценке "плохо". Первоначально (до настройки на конкретную сеть) оно обязательно будет либо завышено, либо занижено (по модулю). Если оно будет завышено, то вы просто не увидите проблему. Представьте, пользователи жалуются на медленную работу приложений, вы запускаете Оценочный Тест, а у вас все горит зеленым, и вы не знаете куда смотреть. Если, наоборот, пороговое значение будет занижено, то вы всегда будете видеть красный светофор, даже если инцидента нет. Если же у вас пять значений, то вы, во-первых, не пропустите инцидент, во-вторых, не будете удивляться, когда "постоянно что-то горит". Таким образом, пять пороговых необходимы только на этапе градуировки системы. В процессе эксплуатации системы мониторинга их можно заменить одним.
Вместо заключения
Чтобы эффективно управлять ИТ-Инфраструктурой, нужно контролировать её "здоровье". Чтобы эффективно контролировать "здоровье" ИТ-Инфраструктуры, нужно, во-первых, уметь измерять соответствующие метрики, во-вторых, знать пороговые значения этих метрик, соответствующие комфортной работе пользователей ИТ-Сервисов. Первое без второго – это как бинокль без настройки резкости: смотреть можно, но увидеть ничего нельзя. Измерение значений метрик большого труда не составляет. Определение пороговых значений – задача существенно более сложная. Есть несколько способов её решения. Наиболее простым и доступным, с моей точки зрения, является Красная Кнопка.
|